
 Faculty of Science, Technology and Medicine
Faculty of Science, Technology and Medicine Faculty of Law, Economics and Finance
Faculty of Law, Economics and Finance Faculty of Humanities, Education and Social Sciences
Faculty of Humanities, Education and Social Sciences Interdisciplinary Centre for Security, Reliability and Trust
Interdisciplinary Centre for Security, Reliability and Trust Luxembourg Centre for Systems Biomedicine
Luxembourg Centre for Systems Biomedicine Luxembourg Centre for Contemporary and Digital History
Luxembourg Centre for Contemporary and Digital History Luxembourg Centre for European Law
Luxembourg Centre for European Law Luxembourg Centre for Socio-Environmental Systems
Luxembourg Centre for Socio-Environmental SystemsImpresso – Media Monitoring of the Past is an interdisciplinary research project that uses computational approach and machine learning to pursue a paradigm shift in the processing, semantic enrichment, representation, exploration, and study of historical media across modalities, time, languages, and national borders. By bringing together historians, computational linguists, and computer scientists, Impresso creates tools and methods that allow researchers and the public to interact with large-scale media collections in new ways.
Over the past months, the Impresso team has been preparing a major release of the Impresso Web App. This milestone brings three key innovations:
- The launch of the Impresso Datalab
- The expansion of our corpus with new titles from France and Switzerland, with collections from other countries to follow soon
- The introduction of a revised data access management system.
Together, these developments strengthen our mission to support cutting-edge, data-driven research on historical media collections.
The Impresso Datalab
With the release of the Impresso Datalab, we open a new chapter for researchers who want to go beyond exploratory browsing and engage directly with data and models. The Datalab complements the Impresso Web App by enabling programmatic access to bibliographic metadata, semantic enrichments, and full text via the Impresso REST API and a dedicated Impresso Python library.
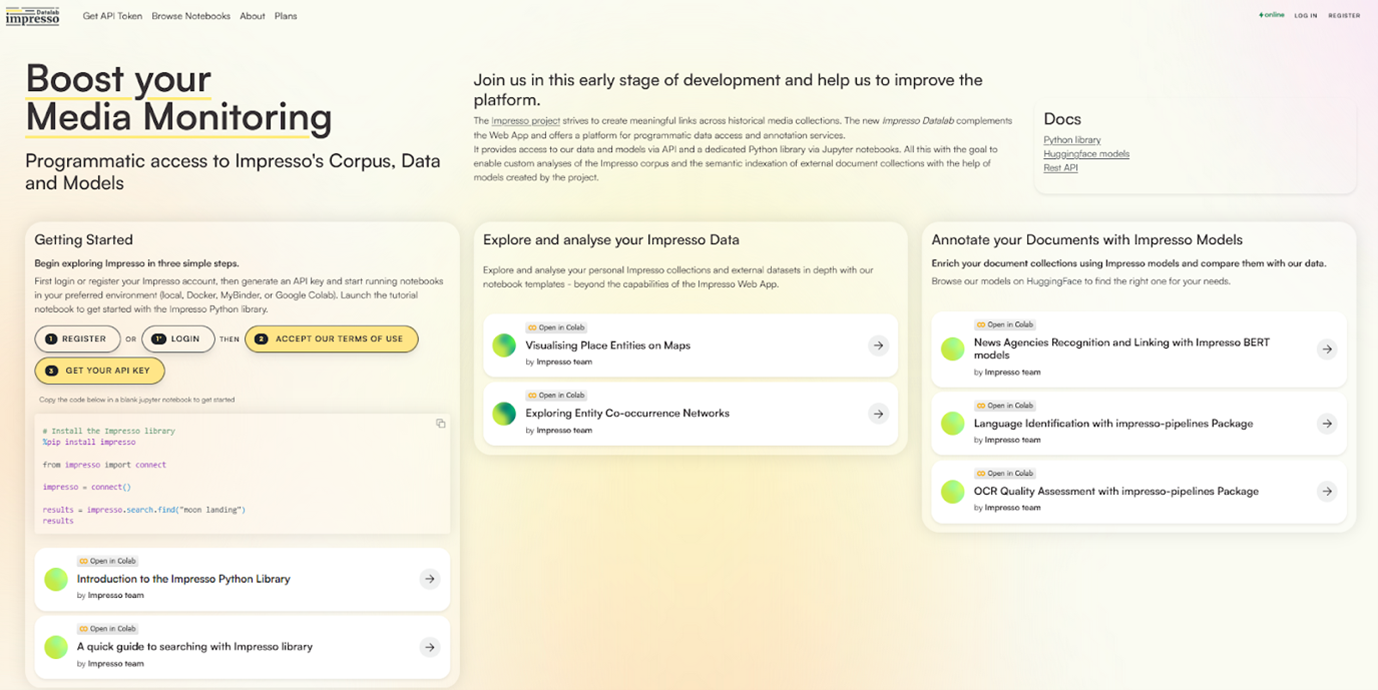
With this release, we offer:
- Programmatic Access to our data: The Impresso Rest API and Impresso Python library provide access to full text, bibliographic metadata, and semantic enrichments in compliance with legal frameworks and institutional constraints of our partners.
- Notebooks for data exploration: Notebook templates are designed to complement the exploratory capacities of the Web App. This includesWith this first release we offer geospatial mapping of location entities contained in a query of collection as well as relational perspectives on entity cooccurrences by means of network visualisations.
- Models and Annotation services to enrich your own data: Researchers can semantically enrich their own data using Impresso’s specialized models and ready-to-use pipelines specifically optimized for historical newspaper text analysis. At this stage, we offer a BERT model for the recognition of European press agencies and pipelines for language identification, topic modelling, named entity recognition and OCR quality assessment.
- Close Integration Web App & Datalab: We strive for seamless, question-driven workflows between both interfaces for scalable reading and versatile exploration. For instance, you can easily export your Impresso Web App query to an Impresso Datalab notebook for in-depth analysis, then return to the Impresso Web App for detailed examination of specific texts.
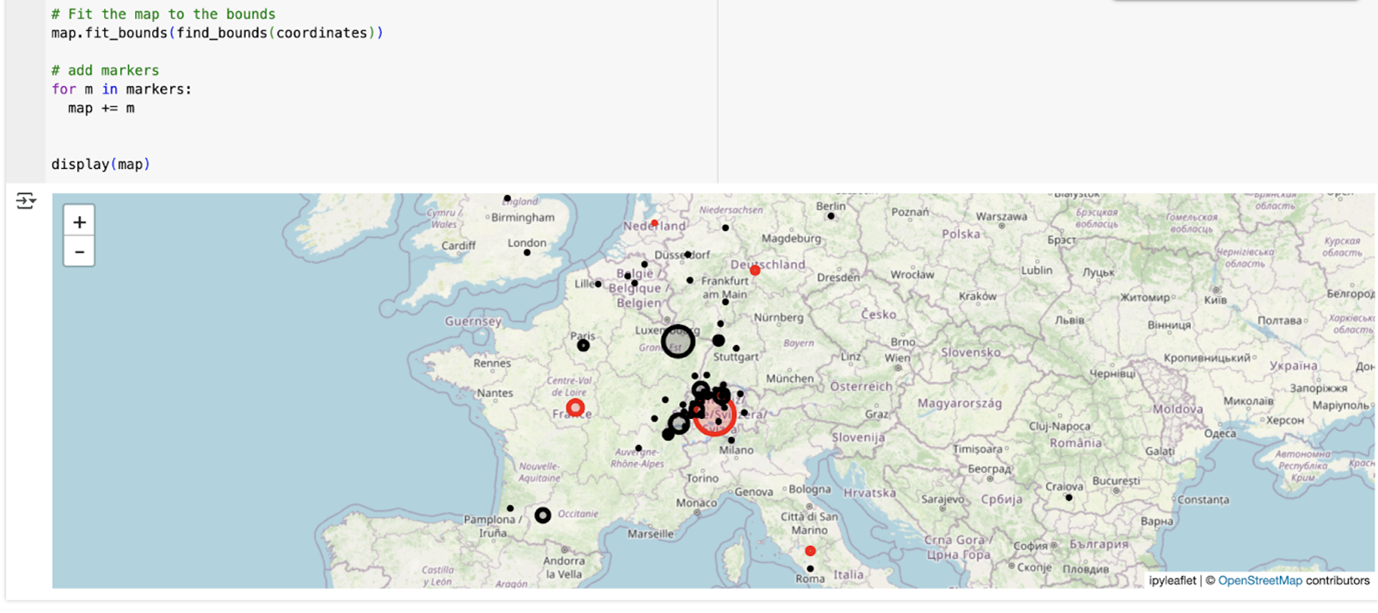
Notebook on Visualising Place Entities on Maps
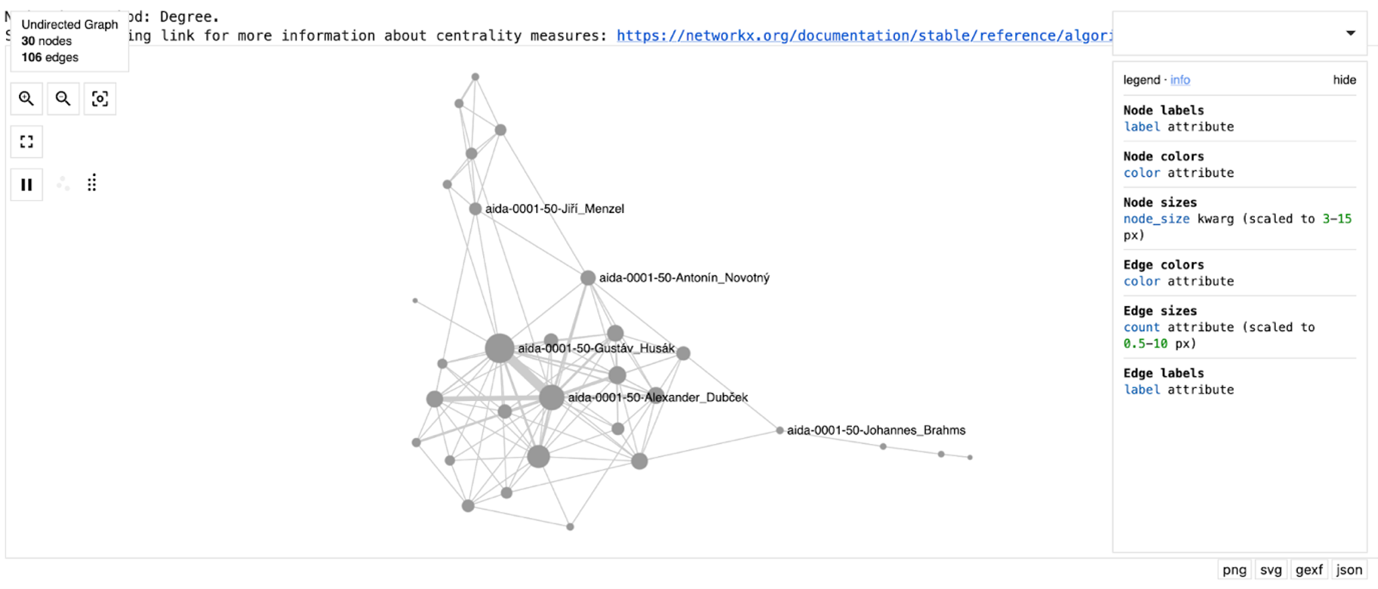
Notebook on Exploring Entity Co-occurrence Networks
For convenience, all notebooks can be run via Google Colab but of course also locally based on user preference.
Impresso Corpus Expansion
We are pleased to announce that we made a first step towards Impresso’s goal to create a corpus of Western European newspapers and radio sources.

A front page of Le Petit Parisien
A first batch of newspapers from the National Library of France (BnF) have arrived. In addition, we have added long awaited titles to our Swiss newspaper collection. This includes “Schweizer Arbeitgeber” and “Schweizerische Handels-Zeitung” coming from the Swiss Economic Archives, a total of 43 titles from the regional collections of Bibliothèque Cantonale Universitaire de Lausanne (BCUL) as well as the German and French editions of the Swiss Federal Gazette also known as Bundesblatt or Feuille fédérale, a rich source which informs about Swiss political and legislative decision-making provided by the Swiss Federal Archives (SFA).
In total, this release adds 53 new newspaper titles, more than 180.00 issues and almost 11 million new content items, such as articles or adverts. From France, this first batch includes major national and regional newspapers such as Excelsior (1910-1920), La Fronde (1897-1929), Le Journal des débats politiques et littéraires (1814-1944), Le Petit Journal illustré (1884-1920), Le Petit Parisien (1876-1944), Marie-Claire (1937-1944), and several others spanning the 19th and early 20th centuries.
New User Access Management System
Alongside the Datalab, we are introducing a new content access management system which allows us to reflect the legal contexts in which our data-providing partners operate as described in our Terms of Use. New user plans reflect the legal frameworks within which our data-providing partners operate, as described in our Terms of Use. Behind the scenes, this new system allows us to grant fine-grained access on the level of individual content items such as newspaper articles or radio broadcasts.

Impresso User plans
This release is only the beginning! The Datalab will continue to grow, with new notebooks, models, and annotation tools designed to support teaching, critical data exploration, and large-scale historical analysis. We warmly invite researchers to create an account, explore the new features, and share their feedback at info@impresso-project.ch.