Fakultät für Naturwissenschaften, Technologie und Medizin
Fakultät für Naturwissenschaften, Technologie und Medizin Fakultät für Recht, Wirtschaftswissenschaften und Finanzwirtschaft
Fakultät für Recht, Wirtschaftswissenschaften und Finanzwirtschaft Fakultät für Geisteswissenschaften, Erziehungswissenschaften und Sozialwissenschaften
Fakultät für Geisteswissenschaften, Erziehungswissenschaften und Sozialwissenschaften Interdisciplinary Centre for Security, Reliability and Trust
Interdisciplinary Centre for Security, Reliability and Trust Luxembourg Centre for Systems Biomedicine
Luxembourg Centre for Systems Biomedicine Luxemburg Centre for Contemporary and Digital History
Luxemburg Centre for Contemporary and Digital History Luxembourg Centre for European Law
Luxembourg Centre for European Law Luxembourg Centre for Socio-Environmental Systems
Luxembourg Centre for Socio-Environmental Systems
Supercomputer finden ihren Einsatz traditionell in Physik, Materialwissenschaften und Chemie. Im Spresso-Projekt, der ersten formellen Zusammenarbeit zwischen dem luxemburgischen Supercomputer MeluXina, der Bibliothèque nationale du Luxembourg und einem interdisziplinären Forscherteam des Centre for Contemporary and Digital History (C²DH) und der Fachbereich Informatik der Universität Luxemburg wurden die Fähigkeiten von Meluxina genutzt, um die automatische Verbesserung der historischen Pressefotografie des 20. Jahrhunderts in großem Umfang durch Deep-Learning-Algorithmen zu untersuchen.
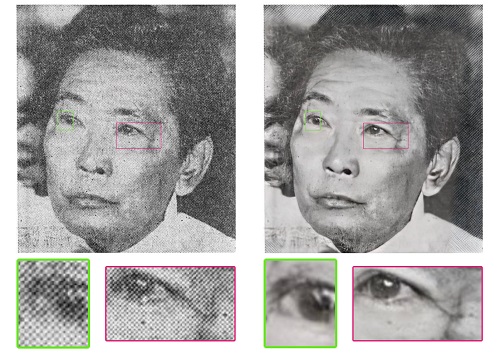
Pressefotografie prägt seit Jahren die Vorstellung von Ländern, Menschen und Ereignissen in den Köpfen von Zeitungslesern auf der ganzen Welt. Als solche sind diese Bilder eine unschätzbare Quelle für Historiker. Zeitungsfotos wurden mit einem Druckraster und seinem charakteristischen Punktmuster gedruckt. Das Spresso-Projekt konzentriert sich auf digitale Kopien dieser Bilder, die vom Impresso-Projekt bereitgestellt wurden. Impresso ist eine Kooperation zwischen dem C²DH der Universität Luxemburg, der EPFL in Lausanne und der Universität Zürich sowie einer Vielzahl an Archiven, Bibliotheken und Zeitungen in Luxemburg und der Schweiz. Spresso hat sich zum Ziel gesetzt, diesen Bildschatz für moderne Forschungsansätze zugänglicher und nutzbarer zu machen.
Durch die Anwendung eines Superauflösungsalgorithmus auf der Grundlage von Deep-Learning-Modellen auf die gescannten Halbtonbilder hat Spresso aus dem Ausgangsmaterial neue synthetische Bilder mit einem oft überraschenden Detailgrad erstellt und die zuvor vorhandenen Artefakte beseitigt, die die Bildqualität verschlechtert haben.
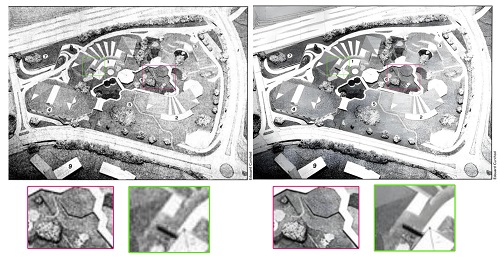
Ausgehend von einem anfänglichen Satz von 10.000 Bildern und unter der Leitung von Prof. Luis Leiva testete Dany Pais da Silva, ein ehemaliger Student des Bachelors in Computer Science, verschiedene Superauflösungsalgorithmen und implementierte eine Prototyp-Pipeline für die Konvertierung der historischen Bilder an den High Performance Computing-Einrichtungen der Universität. Mit der Unterstützung von LuxProvide-Ingenieuren war das Team in der Lage, den Prozess auf den neuen Supercomputer MeluXina zu übertragen und ihn so zu skalieren, dass er auf mehr als 3 Millionen Bilder angewendet werden kann. „Die Zusammenarbeit mit MeluXina und den Ingenieuren von LuxProvide in einem interdisziplinären Projekt war für mich eine hervorragende Gelegenheit, meine Fähigkeiten im Umgang mit Big Data zu erweitern“, berichtet Dany Pais da Silva. Interessanterweise bestand der schwierigste Teil darin, die Daten herunterzuladen, nicht in der Rechenleistung, die für ihre Verarbeitung erforderlich war. „Der Zugang zu den Rohbildern war für uns eine Herausforderung, da wir sie von ihrer ursprünglichen Quelle zu MeluXina und dann zurück in die Räumlichkeiten der Universität übertragen mussten“, erklärt Prof. Leiva.
Der neue Datensatz wird in Zukunft in die Impresso-Anwendung zurückgeführt, um Historikern und der breiten Öffentlichkeit die verbesserte Bildqualität zur Verfügung zu stellen. Die Historikerinnen Estelle Bunout und Marten Düring stellen fest: „Deep Learning bietet großartige Möglichkeiten für die digitale Geschichte. Synthetische Daten, die durch Deep Learning generiert werden, bieten aufregende Möglichkeiten, in einen Dialog zwischen menschlichem Denken und Computeranalyse einzutreten. Sie werfen aber auch grundlegende neue Fragen zu bestehenden Vorstellungen von Authentizität und der Zuverlässigkeit historischer Aufzeichnungen auf. Das Spresso-Projekt wird für uns zum Ausgangspunkt, um zu untersuchen, inwieweit algorithmisch modifizierte Bilder die weitere Anreicherung verbessern, zum Beispiel durch Objekterkennung und -identifikation.“
Lars Wieneke, Leiter der Digitalen Forschungsinfrastruktur am C²DH ergänzt: „Dank der Arbeit von Dany Pais da Silva und Prof. Leiva sowie dem Team von LuxProvide können wir jetzt mit einem Korpus von stark verbesserten Bildern arbeiten, die wir mit fortgeschrittenen Erkennungsalgorithmen bearbeiten werden, um besser zu verstehen, ob die Superauflösung nicht nur eine wahrgenommene Qualitätsverbesserung bietet, sondern auch die Erkennungsraten für eine Vielzahl von Aufgaben wie zum Beispiel die Objekt- oder Personenidentifikation anhebt.“